
Dutch Text Simplification with MUSS
Project links
Skills
About this project
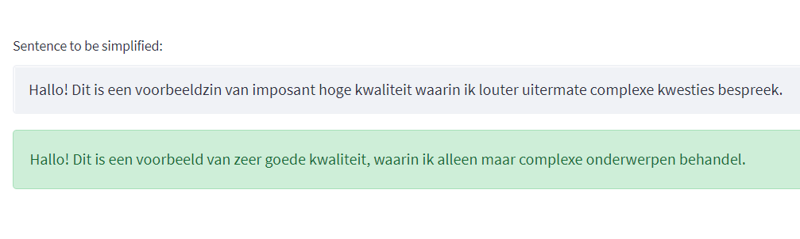
MUSS: Multilingual Unsupervised Sentence Simplification by Mining Paraphrases, as the name suggests, can train a state of the art text simplification model with unlabelled data. This is an implementation of the paper for the Dutch language, which is altered to run on a workstation with 32GB RAM and a RTX 2070 Super 8GB and Azure for training.
Finetuned and deployed a MariantMT model on Dutch data which, even though the MarianMT model is several times smaller than the model used in the paper, mBart, performs great and shows off the amazing capabilities of this text simplification system.